
.svg)

ETL Built the Warehouse. Reverse ETL Put It to Work.



If you've spent any time in the data space, you know ETL. It's the backbone of modern data infrastructure, the reason your analytics team can actually answer the question "how are we doing?" without hunting through five different databases. ETL is the OG. Everyone knows it.
But the data stack has gotten more complex, and a new movement has taken hold: Reverse ETL. While ETL moves data into the warehouse, Reverse ETL moves it back out, pushing warehouse data into the tools your business actually runs on. And just like ETL before it, Reverse ETL is quickly becoming something every data team needs to understand.
Here's the thing: modern organizations don't need to choose between ETL and Reverse ETL. They need both. Together, they form the foundation of an analytics-ready, operationally-activated, AI-ready data stack.
What is ETL
ETL stands for Extract, Transform, Load, and it does exactly what the name implies.
- Extract: Pull raw data from your source systems.
- Transform: Clean, reshape, and standardize it.
- Load: Push the processed data into a central destination.
ETL pipelines pull from a wide range of sources:
CRMs, SaaS applications, databases, marketing platforms, product data and funnel everything into a central warehouse like Snowflake, BigQuery, Databricks, or Redshift.
The "why" behind ETL is straightforward: business data lives everywhere, and you can't do much with it when it's scattered. ETL centralizes it so you can actually use it for analytics and reporting, data warehousing, machine learning, and business intelligence. Without ETL, you don't have a data stack. You have a mess.
Why ETL Became Critical
The SaaS explosion of the last decade created a fragmented data landscape. Companies went from running on a handful of core systems to juggling dozens of tools, each with its own data model, schema, and API. Sales data in Salesforce. Marketing data in HubSpot. Product data in your app database. Finance data in NetSuite. And on and on.
ETL became the connective tissue. By pulling all of that data into a single warehouse, data teams could finally build unified reporting, maintain data consistency, establish trusted metrics, and power centralized analytics. The modern cloud data warehouse wouldn't exist without it, and neither would the data teams that run them.
ETL isn't glamorous. But it's fundamental.
What is Reverse ETL?
If ETL is the inbound lane, Reverse ETL is the outbound lane, and it's a newer concept that's gaining serious momentum.
Reverse ETL takes data from your warehouse and moves it back into the operational tools your business runs on, Salesforce, HubSpot, Marketo, Zendesk, support platforms, ad platforms, and more. Instead of analysts pulling reports from the warehouse, the warehouse pushes intelligence directly into the systems where your teams actually work.
Think of it this way: ETL moves data to the warehouse so you can analyze it. Reverse ETL moves data from the warehouse so you can act on it.
Why Reverse ETL Matters
Here's a problem almost every data team knows intimately: your warehouse is full of incredibly valuable data, and almost nobody outside the data team can access it.
Operational teams, including sales, marketing, customer success, support, are working in their own tools, often with incomplete or stale information. The customer health score your data team built? Stuck in Snowflake. The product usage signals that predict churn? Not in Salesforce. The lead enrichment data that would help your SDR team prioritize outreach? Nowhere to be found in HubSpot.
Data gets trapped in the warehouse. Reverse ETL springs it loose.
When warehouse data flows directly into operational systems, teams can act on it in real time. That means:
- Customer health scoring surfaced in your CRM, not a dashboard nobody opens
- Lead enrichment that makes your sales team smarter before the first call
- Product usage syncing that gives customer success the context they need
- AI workflows that run on clean, current, warehouse-quality data
- Customer personalization at scale, powered by your best data
Reverse ETL doesn't just unlock analytics. It operationalizes the entire data stack.
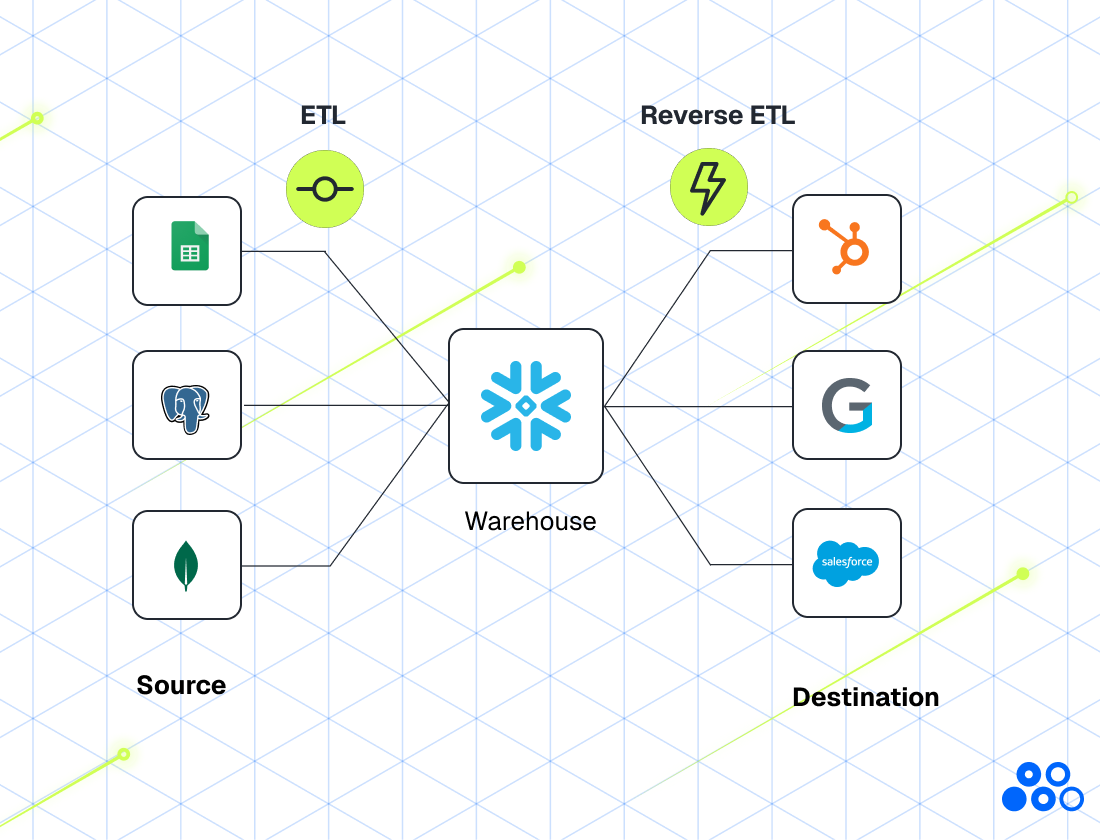
ETL vs. Reverse ETL: Two Sides of the Same Coin
The core difference is directional:
- ETL moves data from source systems into the warehouse.
- Reverse ETL moves data from the warehouse into business applications.
But framing this as a competition misses the point. ETL and Reverse ETL are complementary. ETL centralizes and enriches your data. Reverse ETL activates it. You can't have an effective Reverse ETL motion without clean, reliable data in the warehouse, which means you can't skip ETL. And without Reverse ETL, all that carefully centralized data just sits there, accessible only to people who know how to write SQL.
Modern data architectures need both. ETL answers the question "where is our data?" Reverse ETL answers "what are we doing with it?"
The Challenge: Modern Data Stacks Are a Mess
Here's where things get complicated.
As the data stack has matured, so has the tool sprawl. Today, a typical mid-market data team might be running separate vendors for ETL, Reverse ETL, observability, orchestration, and cataloging. According to Enterprise Strategy Group, nearly half of companies at mid-market scale and above are using 26 or more data vendors.
Every tool has its own setup, its own integrations, its own alerts, its own pricing. And none of them talk to each other particularly well. When something breaks – and something always breaks, you're debugging across multiple platforms, correlating logs from different systems, and trying to figure out whether the problem is in the ingestion layer, the transformation, or the sync downstream.
The operational complexity is real. And it compounds. More tools means more surface area for failures, more vendor relationships to manage, more onboarding time for new engineers, and more budget consumed on infrastructure rather than insight.
The Rise of Unified DataOps
The data teams that are winning right now aren't just adding more tools. They're consolidating.
The smartest engineering and data leaders are looking for platforms that unify the core functions of the data stack, reliable ETL, integrated Reverse ETL, observability, governance, and cataloging, without sacrificing the developer control and flexibility they need to operate at scale.
And with AI reshaping everything, the stakes are higher than ever. AI requires large volumes of high-quality data. It demands clean lineage, strong governance, and infrastructure that can support dynamic updates and real-time streams. Fragmented data stacks can't keep up. Unified ones can.
The future of data infrastructure isn't more tools doing more things in isolation. It's fewer, better tools working together, so your data is reliable at ingestion, observable throughout its journey, and activated across every system that needs it.
The Bottom Line
ETL is still the base. Without it, you don't have a warehouse worth working with.
Reverse ETL operationalizes that warehouse, taking your best data and putting it to work in the tools your business runs on every day.
Together, they form the backbone of a modern, operational data stack. And as AI becomes central to how businesses make decisions, reliable data movement in both directions isn't a nice-to-have. It's a requirement.
The future is reliable. Operational. AI ready. And it moves data in both directions.

.png)






