
.svg)

Your Data Still Isn’t Ready for AI. That’s Exactly Why We Need to Talk About It Again.



A few weeks ago, we hosted a webinar with Matthew Shump from Drata about data readiness for AI. (Haven’t watched it yet? Check out the recording below!) Matthew and his team at Drata have deep experience with preparing data for AI. At the time, it felt like one of those topics that was obviously important, but still a little hard to pin down because everyone was coming at it from a different direction. Some teams were thinking about chat-based analytics. Some were thinking about AI agents. Some were thinking about customer support automation, internal copilots, sales workflows, or product intelligence. All were looking for better ways to activate customer data across the business.
Since then, our team has been to Snowflake Summit and Databricks Data + AI Summit, and the conversations we had there made the webinar feel even more timely. Across both events, the same theme kept coming up with customers: companies are excited about AI, they are experimenting with AI, and in many cases they already have AI features or workflows in production. But they are also running into the same uncomfortable reality. The AI layer is only as useful as the data foundation underneath it.
That may sound obvious, but it becomes a lot less obvious once you get into the details. Most companies already have data moving through their systems. They have pipelines. They have warehouses. They have dashboards. They have modeled tables, operational tools, BI layers, and a growing collection of AI products that all want access to some version of the truth. The issue is not usually that data does not exist. The issue is that the data is not always fresh, trusted, well-modeled, semantically clear, or governed in a way that makes it safe for automated reasoning.
That was the main idea behind the webinar, and after spending more time with customers who are trying to operationalize AI, I think it is worth revisiting. These are my 6 key takeaways from the webinar:
A green pipeline does not mean the data is ready
One of the traps we talked about in the webinar is that traditional pipeline health can create a false sense of confidence. A job can run successfully. A dashboard can refresh. A table can be queryable. Every box in the orchestration tool can be green. And yet, the data being served to an AI system can still be stale, incomplete, misleading, or missing the business context required to use it correctly.
In the dashboard era, a human was usually still in the loop. Someone saw the number, questioned it, compared it to another report, asked the analytics team, or noticed that something looked off. That did not make traditional analytics perfect, but it did create natural friction. AI removes a lot of that friction. It makes it much easier for someone to ask a question and get a confident answer immediately. That is powerful when the answer is grounded in the right data. It is dangerous when the system is reasoning over stale snapshots, ambiguous fields, or metrics that have drifted away from their original definitions.
This is why “data readiness” has to mean more than pipeline uptime. AI-ready data needs freshness, quality, lineage, observability, governance, and business-aligned models. It also needs context. A pipeline can move a field from one system to another, but it usually does not explain what that field means, who owns it, whether it is approved for a particular use case, or how it should be interpreted when the business asks a question in plain English.
That is the gap a lot of teams are running into right now. They have data movement, but not enough data meaning.
The real bottleneck is interpretation
The most useful part of the webinar, at least for me, were the real-world situations that Matthew’s team at Drata have faced. He grounded the whole topic in the operational reality of running a modern data team. Drata, like a lot of companies, has centralized data and invested in structured definitions, modeling, and governance. That is the right move, but it also creates a familiar tension. Business users want more access to data, and they want it faster. Data teams want to enable that access without turning the warehouse into a choose-your-own-adventure book of raw tables, inconsistent metrics, and undocumented assumptions.
This is where AI gets interesting. In theory, AI can help reduce the dependency on analysts for every exploratory question. A finance, product, sales, or operations power user should be able to ask questions of governed data without writing every query by hand or waiting for the analytics team to pick up every request. Matthew talked about how this changes the role of self-service: not by giving everyone uncontrolled access to everything, but by creating different modes of access for different personas.
That distinction is important. Power users can be given more flexibility because they have enough domain knowledge, skepticism, and technical fluency to validate what they are seeing. Broader business users may need a more constrained experience, where AI is operating on certified metrics, curated models, and safer interfaces. The goal is not to pretend that everyone instantly becomes an analyst because they have a conversational interface. The goal is to let more people answer more of their own questions while preserving enough structure that the answers still mean something.
In other words, AI can help with the bottleneck, but only if we give it something better than raw access. Otherwise we are not democratizing insights. We are democratizing confusion.
Raw data is not a foundation for trustworthy AI
AI self-service sounds simple: connect an agent to the warehouse, let users ask questions, and let the model figure it out. Anyone who has spent time around real enterprise data knows why that falls apart quickly.
Warehouses are messy because businesses are messy. There are operational source systems, historical migrations, deprecated fields, overlapping definitions, tenant-specific patterns, renamed metrics, half-documented transformations, and business logic that lives in a mix of dbt models, dashboards, spreadsheets, and people’s heads. Giving an AI agent access to all of that does not magically create understanding. It gives the agent a much larger surface area for misinterpretation.
Matthew gave a great example during the webinar. He asked what sounded like a straightforward question: show the top accounts by ARR and include their signup date. Different AI interfaces came back with different answers. The problem was not that the systems were useless or that the models were broken in some dramatic way. The problem was interpretation. What does “signup date” mean? Product activation? Contract start? Closed-won date? Something else? What does ARR mean in that context? Current ARR? Starting ARR? Booked ARR? Pipeline? Depending on how the system resolves those terms, it may produce answers that are technically defensible but still wrong for the user’s intent.
That is exactly the kind of problem data teams need to solve before AI becomes deeply embedded in business workflows. The fix is not just better prompting. It is better context engineering around the data itself. Semantic definitions, certified queries, modeled entities, metric documentation, data catalog, lineage, and evaluation sets all become part of the AI architecture. They are not side projects. They are the mechanism that helps the AI interpret the business correctly.
This is also why modeled data matters so much. A well-designed analytical model narrows the space of possible interpretation. It gives the AI a safer set of entities, relationships, and definitions to work with. That may reduce some flexibility compared to querying raw source tables directly, but it dramatically improves consistency. And for most business use cases, consistency is not optional. If two executives ask the same question, they should not get three different answers because the AI made three different assumptions.
Freshness should be treated like an SLO
Another idea from the webinar that has stuck with me is that freshness needs to become a first-class concern. Data teams already think in terms of pipeline failures, latency, completeness, schema changes, and distribution shifts. But in AI workflows, freshness becomes even more visible because the system may continue producing answers long after the underlying data has stopped representing reality.
Different use cases have different freshness requirements. Executive reporting may be fine with daily updates. Product usage recommendations might need data from the last hour. Fraud, security, inventory, and operational workflows may need data that is fresh within minutes or seconds. The important thing is not that every AI use case needs real-time data. The important thing is that the freshness expectation should be explicit.
If an AI agent is helping with a task, it should know whether the data is fresh enough for that decision. If it is not, the system should degrade gracefully. That might mean warning the user, refusing to answer, falling back to a safer workflow, or flagging the output as based on stale data. What it should not do is keep responding as though nothing has changed.
This is one of the reasons observability and lineage become so important. Observability helps detect when something is wrong: freshness gaps, schema changes, volume anomalies, completeness issues, or segment-level shifts. Lineage helps explain where the problem came from and what it affects downstream. In a traditional analytics stack, that might mean identifying which dashboards are impacted. In an AI-enabled stack, it also means identifying which agents, workflows, recommendations, and operational systems may now be reasoning over bad inputs.
Silent failures were already painful. AI makes them more expensive.
Dashboards are not dead, but their job is changing
The webinar also touched on a question that comes up constantly now: do dashboards still matter if people can just ask an AI assistant for the answer?
I think the answer is yes, but the role of dashboards gets narrower and more intentional. Dashboards are still the right tool for stable, shared views of the business. If a leadership team reviews the same operating metrics every week, there is no reason to regenerate that view through a conversational interface every time. If a metric is important enough to be part of a recurring business rhythm, it probably deserves a durable, trusted surface.
Where AI changes the picture is exploration. A lot of dashboards became bloated because they were trying to serve every possible follow-up question. That is how teams end up with 12 tabs, 25 filters, and a dashboard that technically contains the answer somewhere if you already know how to find it. Conversational AI is a better fit for some of that long-tail exploration, especially when it is grounded in the same certified models and definitions as the dashboard.
So the future is not dashboards versus AI. It is dashboards for shared operating truth, and AI for guided exploration, investigation, and follow-up. The two should complement each other. If they are grounded in different definitions, they will just create another trust problem.
Activation is where the architecture becomes real
The last piece of the conversation that feels especially important after the summits is activation. It is one thing to centralize data and let people analyze it. It is another thing to push trusted, modeled data back into the systems where people actually work.
That is where reverse ETL fits into the AI readiness conversation. Historically, reverse ETL has been about taking modeled data from the warehouse and syncing it into operational tools like CRMs, customer success platforms, or marketing systems. That pattern is still valuable. But now those downstream systems increasingly have their own AI features, agents, copilots, and automation layers. Feeding those systems with trusted data becomes part of the AI foundation too.
This is where a hub-and-spoke architecture starts to make sense. The warehouse or data platform becomes the hub where data is centralized, modeled, observed, and governed. The spokes are the operational systems, AI tools, dashboards, and workflows that consume that data. But the spokes need to be managed carefully. If every downstream system has its own definition of customer health, churn risk, product usage, or account value, then AI will amplify those inconsistencies instead of resolving them.
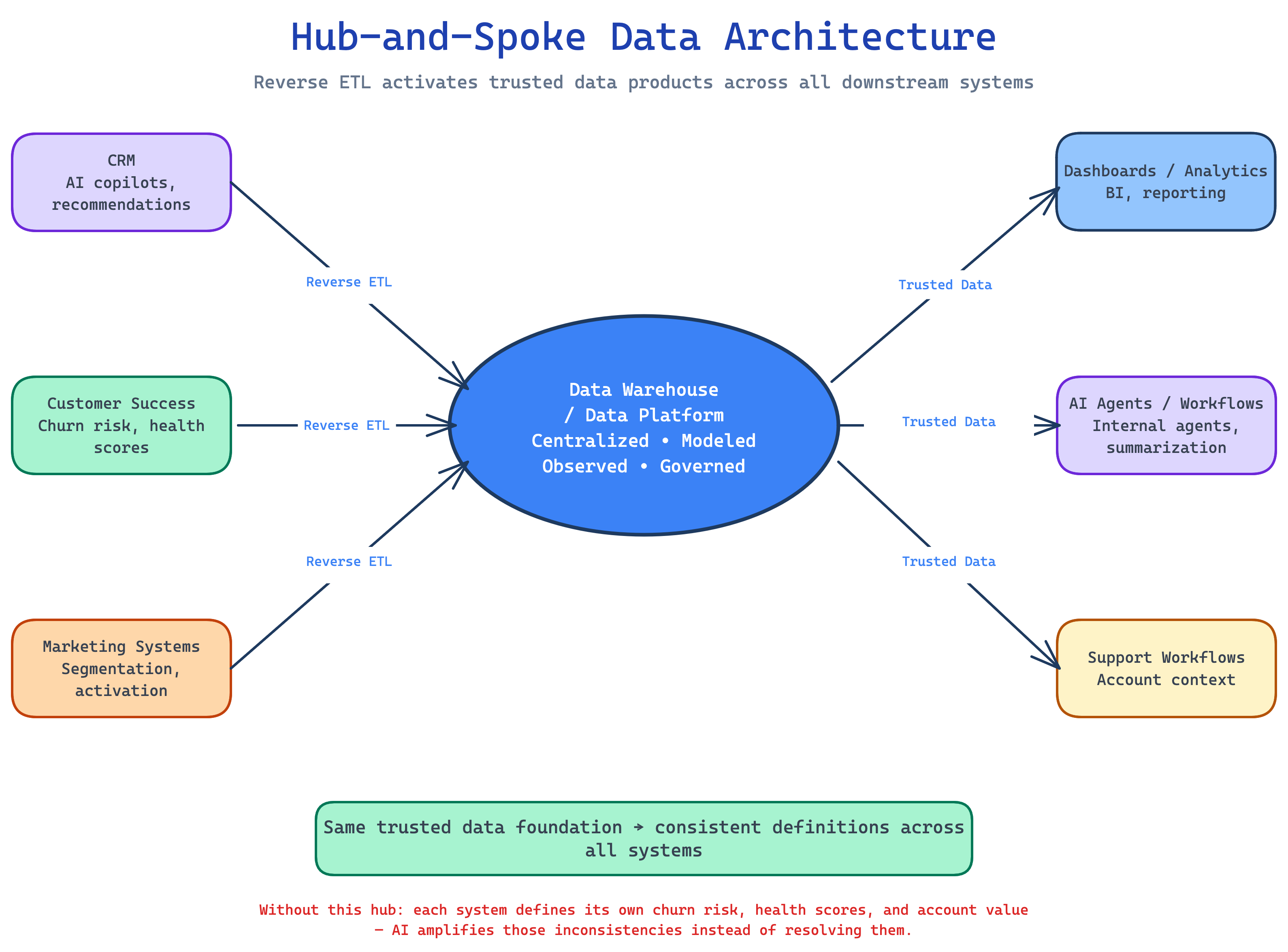
The goal should be to activate the same trusted data products across analytics, operations, and AI workflows. That way, when a customer success manager sees a recommendation in a CRM, a support workflow references account context, and an internal agent summarizes customer risk, those systems are all working from the same foundation.
That is easy to say and hard to do. But it is exactly where the value is.
The retrospective
AI-ready data is not just clean data. It is fresh, modeled, observable, governed, semantically rich, and activated in the right places. After Snowflake Summit, Databricks Data + AI Summit, and a lot of customer conversations, I feel even more confident in that framing.
The companies making real progress are not treating AI as a layer they can simply drop on top of an existing data mess. They are starting with specific use cases. They are asking what data the use case needs, how fresh it needs to be, what definitions matter, which users should have access, what guardrails need to exist, and how outputs will be validated. They are thinking about human workflows and AI workflows together. They are also accepting that this will be iterative, because business definitions change, source systems change, product behavior changes, and user expectations change.
That may be less exciting than a demo where an AI agent answers a question in five seconds, but it is much closer to the work that actually matters. AI does not remove the need for strong data foundations. It raises the stakes.
The model can be impressive. The interface can be polished. The workflow can feel magical. But if the data underneath is stale, ambiguous, fragmented, or poorly governed, the system will eventually produce the wrong answer with confidence. That is the risk technical teams are trying to manage now, and it is why data readiness has moved from a background concern to one of the central questions in enterprise AI.
The webinar was about that shift. The conversations since have only made it clearer.

.png)






