
.svg)

What I Learned Moving from Software Engineering to Data Engineering


I used to think moving from software engineering to data engineering would feel like switching careers.
It didn’t.
Honestly, it felt more like switching neighborhoods.
I’ve been a software engineer for 20 years, but I never specialized in one area. I’ve worked the full stack - frontend, backend, embedded, platform engineering - with multiple languages and frameworks. That experience also included data projects, such as building an enterprise-scale analytics application for a logistics company that measured global shipping performance and costs. One thing remained the same across all those languages, frameworks, and projects: the mental model. It didn’t matter what the stack was, if the team and I applied best practices, built iteratively, and tested well, then the project was a success.
It’s Not a Different Job, It’s a Different Layer
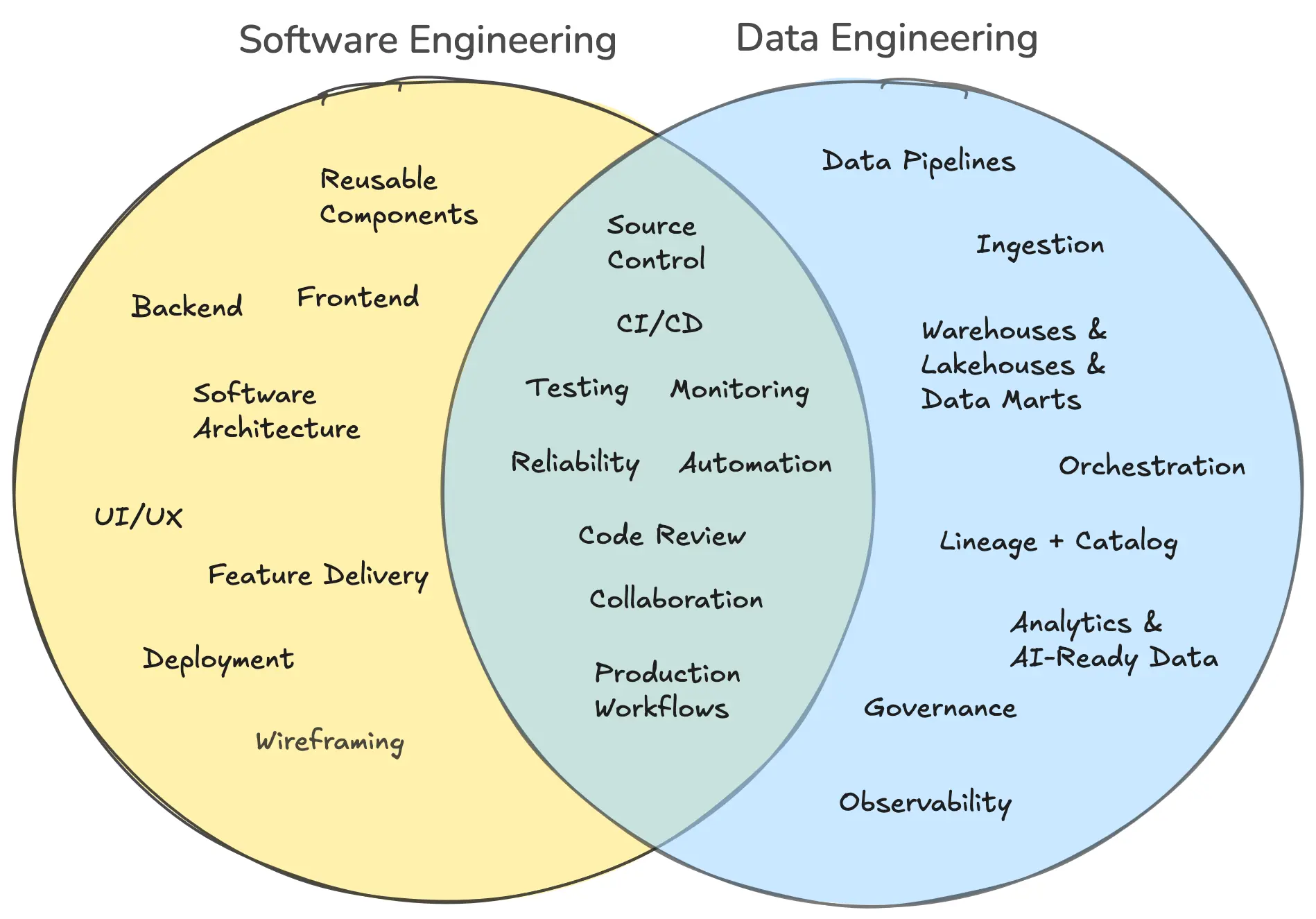
When I moved to data engineering, sure, the tools changed. The nouns changed. Instead of talking about APIs, frontends, deploys, and app state, I started talking about pipelines, warehouses, orchestration, transformations, and data observability. But under all of that, a lot of the mental model felt weirdly familiar. The same mental model and best practices I used as a software engineer were immediately applicable to data engineering.
That was probably the biggest surprise.
When I first looked at modern data engineering, I expected something a little more... old school. More scripts. More manual work. More “someone runs this SQL and hopes for the best.” When I built out the data pipeline for the logistics company, we used SSIS with manual testing and virtually non-existent source control. It went against that mental model I had developed over the years.
But modern data engineering is actually pretty close to software engineering in all the ways that matter. You’re still building systems. You’re still thinking about reliability, maintainability, testing, environments, deployment, debugging, and how not to ruin production on a Friday afternoon.
And maybe most importantly, you’re still working in source control.
That part really hit me. A lot of the newer data stack is built around workflows software engineers already understand: Git branches, pull requests, CI/CD, code review, testing, promotion across environments, and reproducible deployments. That’s a huge shift from the old stereotype of data work being this mysterious pile of notebooks, one-off queries, and tribal knowledge.
This is where the idea of DataOps starts to make sense. If DevOps brought engineering discipline to software delivery, DataOps is basically that same energy applied to data systems. You want changes to be versioned. You want tests. You want automation. You want a clean path from development to production. You want fewer “who changed this table?” moments and more confidence that your pipelines won’t quietly wreck downstream reporting.
That was one of the biggest “oh, I get it now” moments for me. Data engineering isn’t some side quest away from software. It’s increasingly just software engineering aimed at data problems.
And that’s exactly why companies like Matia make sense. If modern data teams are expected to operate with the same discipline as software teams, versioning changes, managing deployments, monitoring reliability, understanding downstream impact, and keeping governance tight, then they need tooling that supports that reality. Matia brings a lot of those pieces together by helping teams manage data movement, monitor quality, trace lineage, and understand how data is actually used across the stack, without forcing them to stitch together a dozen disconnected tools.
The Modern Data Stack Feels Surprisingly Familiar
The ecosystem feels familiar too. This is a very imperfect analogy, but I find it useful:
In frontend engineering, there are a few big anchors that shape how you think about the stack. React, Angular, Vue, whatever. Once one of those is in place, a whole ecosystem starts to form around it. Then you add the usual supporting cast, stuff like routing, state management, data fetching, component libraries, build tooling. Some tools become almost default choices, even if they’re not technically mandatory.
Data engineering feels a lot like that.
You’ve got big anchors like Snowflake and Databricks. Those aren’t exactly the same kind of thing as React or Vue, but they play a similar role in the sense that they become central platforms around which the rest of your workflow starts to organize itself. Once a team commits to one of those, a whole toolchain tends to follow.
And then you’ve got tools like dbt, which kind of reminds me of the “everyone ends up using this eventually” category in frontend. Not because it’s the only answer, but because it gives structure to a problem space that gets messy fast. It brings order to SQL transformations in the same way a good frontend library brings order to state or data fetching. It gives teams conventions, repeatability, and a shared way to work.
That was another thing I learned pretty quickly: the hard part usually isn’t writing one transformation. The hard part is making hundreds of them understandable, testable, reviewable, and safe to change over time.
Which, again, is a very software engineering problem.
Same Engineering Instincts
There are differences, of course.
Data has a nastier relationship with reality than a lot of application code does. In software, if a function gets the wrong input, maybe a feature breaks. In data, if upstream data is late, malformed, duplicated, missing, or defined differently than you expected, the problem can quietly ripple everywhere. Dashboards drift. Metrics stop matching. Models degrade. People make decisions based on bad information.
So one lesson I learned fast is that data engineering has a lot of “systems programming for ambiguity” energy. You’re not just building logic. You’re constantly negotiating with weird source systems, incomplete assumptions, and business definitions that absolutely sounded settled until five minutes ago.
That part can be chaotic, but it’s also what makes it interesting. You’re not just shipping code. You’re building trust. The end product isn’t always a UI or an API. Sometimes it’s a table, a model, a metric, or a pipeline that other people depend on to understand what’s happening in the business. That’s a different kind of product surface, but it is still a product surface.
And that might be the simplest way I’d explain the shift now:
In software engineering, you’re often building experiences directly for users. In data engineering, you’re often building the systems that make those experiences, decisions, and insights possible.
Different layer, same engineering instincts.
The other thing that stands out to me now is how thin the line has gotten between software engineer and data engineer. It used to feel like these were pretty separate identities. Now, not so much.
Modern data teams use source control, CI/CD, testing, infrastructure automation, code review, reusable components, and platform thinking. Software engineers are increasingly expected to understand analytics, event streams, data models, and AI-adjacent workflows. And with AI showing up everywhere, clean and meaningful data suddenly matters even more. Models are only as useful as the data behind them, and that means the people who can build understandable, reliable data systems are in a very good spot.
So if you’re a software engineer wondering whether data engineering is a huge leap, I don’t think it is. It’s a shift, for sure. You’ll learn new tools, new patterns, and a new set of failure modes. But the core instincts, thinking in systems, designing for change, using source control, automating what should be automated, and making things reliable for other people, transfer over surprisingly well.
The line between software and data engineer has never been thinner.
And with AI raising the stakes on having clean, understandable, meaningful data, this might be one of the best times to make the jump. That shift is exactly what platforms like Matia are built for, bringing structure and trust to modern data workflows.
If you’re a software engineer who’s been thinking, “maybe I should get deeper into data,” I’d say go for it. The gap between the two worlds is smaller than ever, and I’m figuring that out in real time through my work with Matia. If that sounds like your kind of thing, follow along as I keep digging deeper into data engineering, DataOps, and the tools shaping this space. Matia is growing quickly, we’ve got a lot in the works, and I have a feeling the next chapter is going to be a fun one.

.png)






