
.svg)

Semantic Undo at Scale: How We Built Replay-Based History for Lineage


Welcome to the first blog post from Matia’s Engineering Team! If you like code, and you like data, this post is for you!
At Matia, we're building a data lineage capability to track relationships between tables, warehouses, data lakes, and BI tools, helping teams understand complex data pipelines. Users can reveal upstream/downstream dependencies, track table relationships, and drill into deep table/column-level lineage to debug errors or understand how deprecations propagate through their systems.
As our users began managing larger datasets and more complex layouts, it became clear that a reliable undo/redo mechanism was essential for a seamless experience like revealing deep lineage (which can produce hundreds of nodes and edges), toggling column-level details, or reverting layout changes, we knew we needed a robust solution.
Adding undo/redo to an interactive lineage canvas forced us to confront graph size, async fetches, and design patterns from Memento, through Command Pattern, to Event sourcing. Here’s what we shipped, what we called it, and what we’ve done differently.
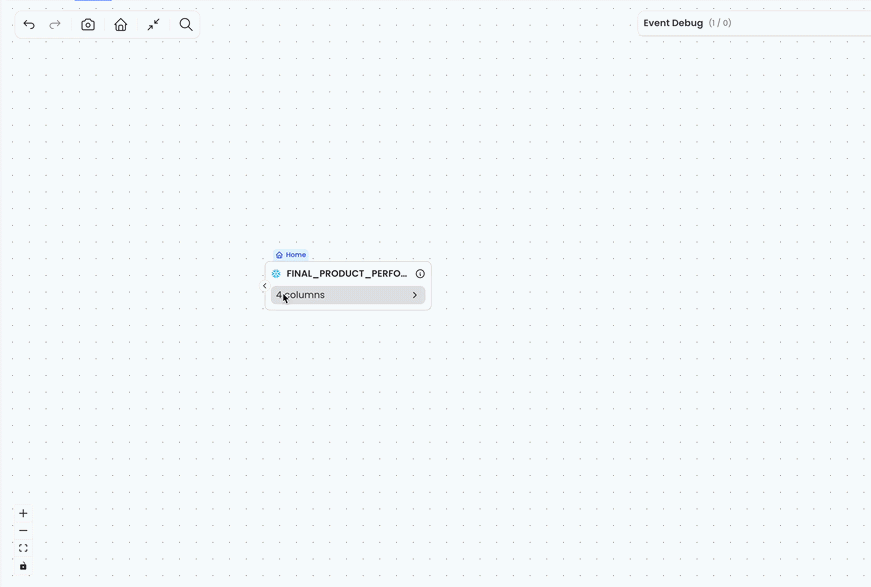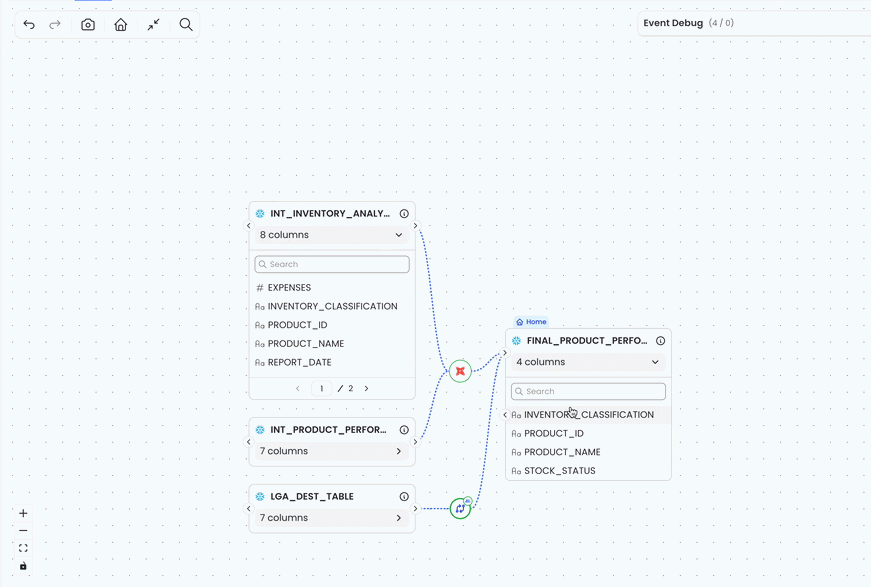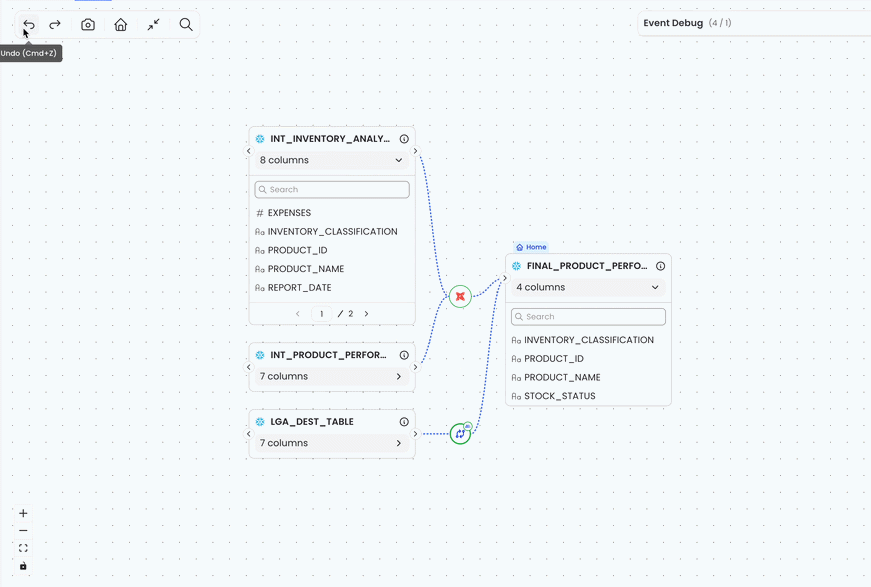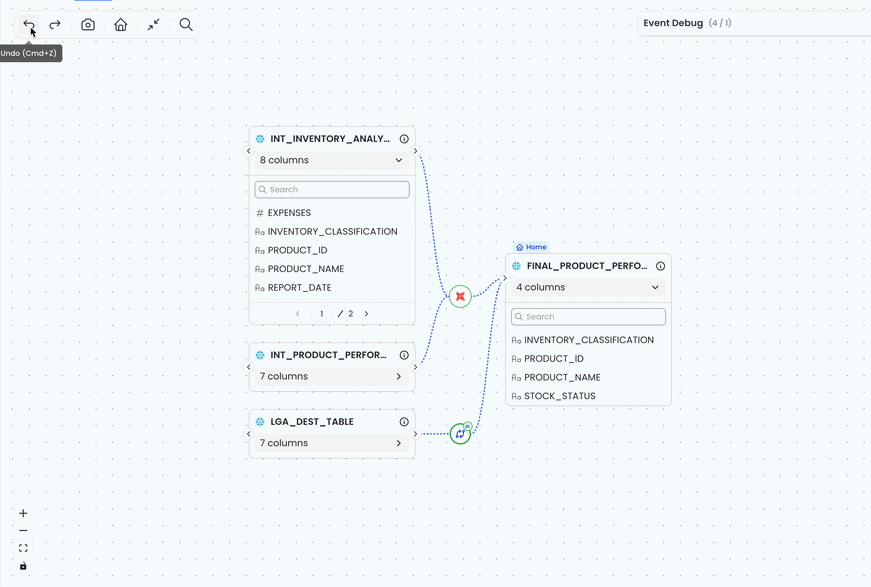
From Full State to User Intent: Our Undo Model
Undo sounds simple until your state is a graph, your mutations are async, and one visible “action” is three network phases. We looked at snapshot-based tools like Zundo and diff-based systems like Meta’s Travels.js, but the core question was “what should count as one undoable user intent?” We call our current approach as checkpointed forward-command replay - we record semantic graph operations, batch related sync events into one undo step, and periodically fold old history into a snapshot anchor. That gives us selective tracking, deterministic replay, and undo units that match how analysts actually explore lineage.
That design choice came only after we hit the limits of the two obvious options. A pure snapshot approach is simple, but expensive at lineage scale. If one graph snapshot takes 1 MB, keeping hundreds of undo states quickly becomes 100 MB or more. As the graph grows and each reveal adds hundreds of nested nodes, edges, and layout-related data, those snapshots can easily double in size and become untenable. Diff-based approaches, such as Travels-style JSON patches, reduce the cost of storing full snapshots, but they still work at the level of structural state changes. That is not the unit we care about most. In our lineage graph, one user action can touch large parts of a deeply nested tree, and the resulting patch chain can become noisy and expensive to reason about.
Our current approach sits in the middle: we keep a rolling checkpoint, then store semantic operations on top of it. Instead of remembering every full graph state or every low-level JSON change, we remember user-level intents like “reveal upstream lineage” and replay the remaining operations from the checkpoint during undo/redo. This gives us bounded memory, better undo granularity, and a model that matches how users think about the canvas.
Async batching needs transaction boundaries
In Matia’s lineage tool, one user action is often not one state mutation. For example, when a user reveals table columns, the UI may first mark the column area as loading, then request data from the server, then apply the returned columns, then clear the loading state. To the user, this is one intent: “reveal these columns”. Undo should roll back that whole intent, not just turn a spinner on or off.
The difficulty is that these phases can be async, and async work can overlap. Imagine the user starts revealing columns for Table A, then quickly reveals columns for Table B before Table A’s request finishes. The mutations may arrive in this order:
- Table A starts loading
- Table B starts loading
- Table B finishes and adds columns
- Table A finishes and adds columns
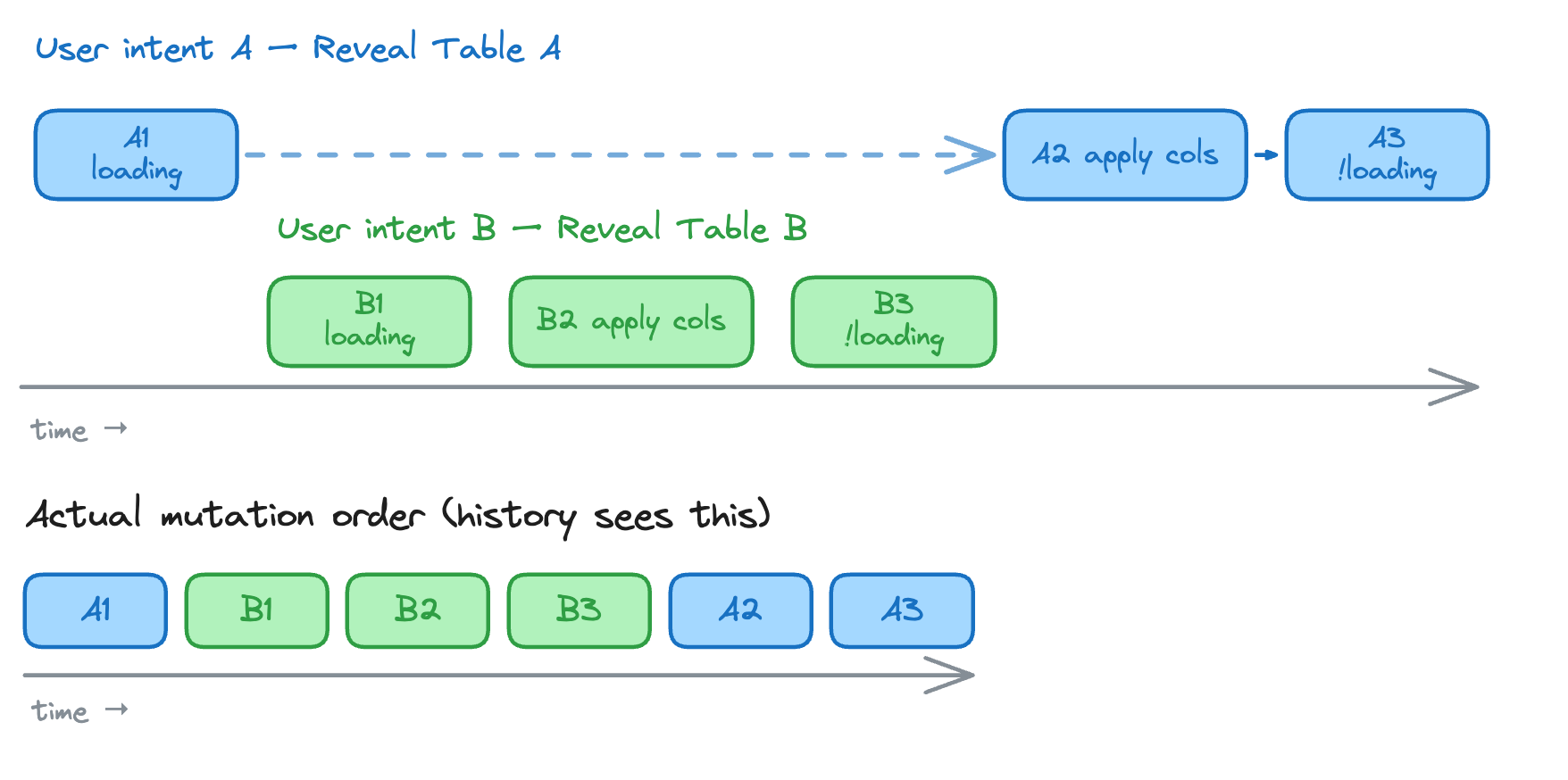
If we try to “start recording a batch” and then collect whatever mutations happen next, we can no longer tell which mutations belong together. Is Table A’s late response part of the most recent batch? Without a stable boundary, the history layer has to guess.

This is where our current approach uses transactional events. Each transactional event gets a transaction id at emit time, before the async work races with anything else. All events that belong to the same user intent use the same transaction ID, so the undo stack can group them deterministically even if their mutations are interleaved with another action. Existing tools like Zundo or Travels.js can batch sync and async updates when the sequence is clear, but they do not solve this identity problem for overlapping work. Assigning the batch identity upfront helps us to solve race condition problems to handle batching properly for transactional events.
What do you even consider a batch?
That became the first real question when we looked at manual tracking options like Travels.js and Zundo. Our graph state lives in a Zustand store wrapped with Immer, and that setup does not give us a clean “Immer has finished producing this update” hook that we could safely use as a history boundary. We experimented with attaching a mutation ID so a store subscription could recognize which update had just landed, but that was only a workaround for observing completion, not a real batching model. Once we started thinking through async flows and race conditions, it became clear that completion detection was the wrong center of gravity.
What we needed was to define the batch at the semantic layer: related graph operations share a transaction ID, and the event store treats them as one undo step.
The Investigation: Using AI to Find the Right Undo Model
We used AI tools to move quickly through the design space, not to blindly generate the final architecture. Agentic coding tools gave us a tight feedback loop: prototype a pattern, wire it into a few lineage flows, expose the edge cases, then decide whether to keep or discard it. That led us to what we started calling a “disposable code” mindset. Because AI made prototypes cheaper, we could be more rigorous in exploration instead of more attached to the first working version.
Over a couple of days, we tried and discarded several approaches that would normally have required much more engineering time to evaluate properly. The result was not a textbook Memento stack, a classic Command pattern, or full Event Sourcing. We landed on the hybrid approach that matched our product constraint. We call it checkpointed forward-command replay. In practice, that means we record semantic operations, batch related async phases into one user-visible undo step, keep a rolling checkpoint as an anchor, and implement undo by removing the last operation and replaying the remaining operations forward.
Research highlights
Zundo / Zustand temporal middleware: Zundo was attractive because it already understands Zustand, but its default model tracks store-level changes rather than user intent. For lineage, we needed “undo reveal upstream lineage”, not “undo loading flag” or “undo the third internal mutation.” We also found that safely controlling tracking around batched async work was difficult. Manual pause/resume workaround introduced race-condition concerns.
Immer patches: Immer patches gave us a lower-level diff mechanism, but they pushed us toward structural history instead of semantic history. They also didn’t remove the hardest parts: large graph payloads, non-serializable derived state, and complex replay behavior. For our use case, patch chains felt close to the memory and complexity profile of diff-based or memento-like solutions without giving us the undo granularity we wanted.
Command pattern: We prototyped commands with both execute() and undo(). AI made this surprisingly fast because much of the forward logic already existed, and agents could often generate plausible inverse logic in one pass. But the long-term cost was clear: every graph action would need a correct inverse, plus tests proving that repeated undo/redo sequences behave as expected. Stateful commands also made the history stack harder to reason about. We kept the useful part, forward commands, and dropped per-command inverse logic. In the current design, commands only know how to apply themselves from a snapshot; undo is structural - pop from history and replay forward from the checkpoint.
Travels.js / diff-based tracking: Travels.js was interesting because it offers efficient diff-based time travel on top of mutative.js. But adopting it meant introducing a separate state system and bridging it back into our existing Zustand graph store. That bridge became a significant integration layer, and early proof-of-concept migrations exposed behavior that didn’t line up cleanly with our existing graph logic. Most importantly, we still couldn’t get comfortable with race conditions around manual tracking and async batching. The lesson was that diff-based time travel is powerful, but our problem was less about capturing every state transition and more about preserving meaningful lineage operations.
Our Solution: Checkpointed Forward-Command Replay
We shipped a client-side undo layer built around semantic operations, transaction IDs, and a rolling checkpoint.
Instead of storing a full graph snapshot for every undo step, we keep one baseSnapshot as an anchor and record a bounded history of forward operations on top of it. Any undoable state can be reconstructed as: “base snapshot + replay of the remaining operation history.”
That gives us the memory profile we wanted without forcing every feature to implement its own inverse undo() logic
At the core of this approach is replay:
const replay = () => {
let state = baseSnapshot;
const flatEvents = history.flatMap((entry) => entry.events);
// Replay serializable graph state only — events do not capture layoutEngine
for (const event of flatEvents) {
state = applyEvent(state, event);
}
// Retained mode: reconcile untracked layoutEngine with replayed graph state
// layoutEngine is excluded from event history (non-serializable), so after replay
// we diff graph nodes vs layout nodes:
// stale (in layout, not in graph) → remove from layout (+ related edges)
// new (in graph, not in layout) → add to layout (+ related edges)
LayoutEngineTools.for(state).retainedMode();
};This also addresses the serialization problem in a pragmatic way. We do not try to serialize every piece of graph infrastructure. Serializable operation payloads are captured in event snapshots, while derived or non-serializable pieces, such as our layout engine, are reconstructed during replay.
That pattern gives us room to grow. If more non-serializable infrastructure is added to the store later, it does not need to be copied into every history entry. It can follow the same model: keep undo history focused on semantic graph operations, and rebuild runtime-only infrastructure when deriving state.
Transaction-Based Event Grouping
At emit time transactional events get their transactionId - _txId; the event store then uses that _txId to decide whether the event should start a new undo entry or join an existing one. In other words, the history stack stores semantic undo units, not raw mutation-by-mutation steps.
const appendToHistory = (event) => {
const txId = event._txId;
if (txId) {
const existingBatch = history.find((entry) => entry.txId === txId);
if (existingBatch) {
// Same transaction still open — extend current undo unit
existingBatch.events.push(event);
return;
}
// New transaction - start a new undo unit
redoStack = [];
history.push({ txId, events: [event] });
return;
}
// No transaction id - each emit is its own undo unit
redoStack = [];
history.push({ txId: undefined, events: [event] });
};For example, revealing column-level lineage can spawn new tables, connect them, open their columns, and highlight column relationships. Each spawned table may trigger its own async “expand columns” flow: loading state, fetched columns, rendered columns, and error or settled state. On their own, those would be separate operations. But when they are part of the original “Reveal Column Level Lineage” action, we pass the parent transaction ID into the column expansion flow, so all of those child events are appended to the same history entry.
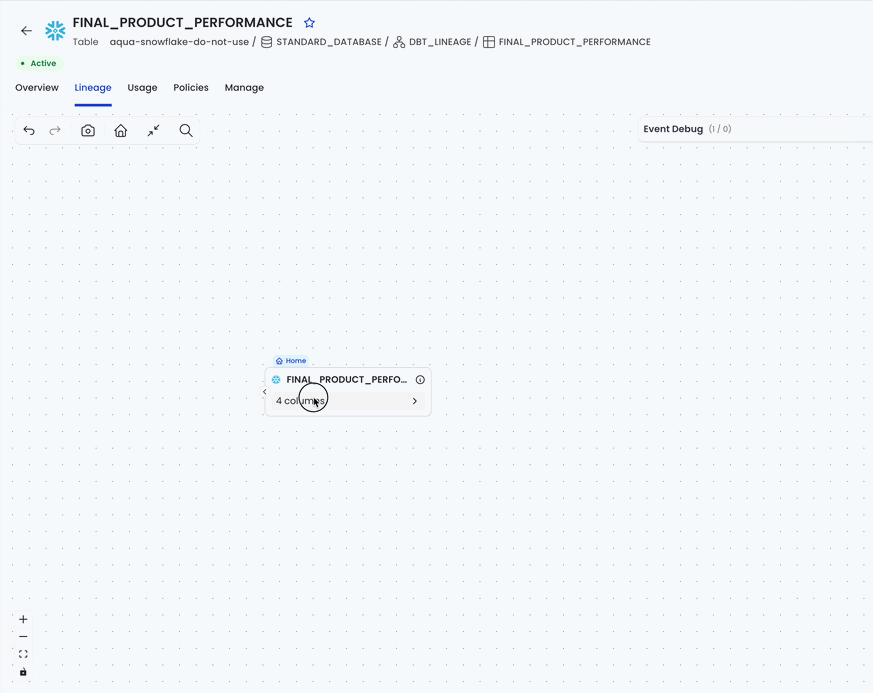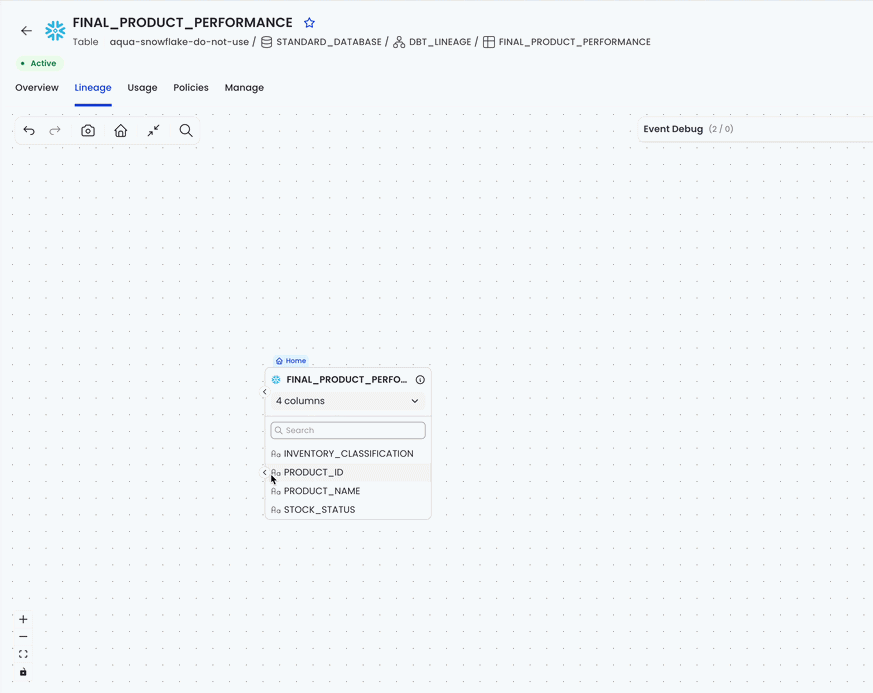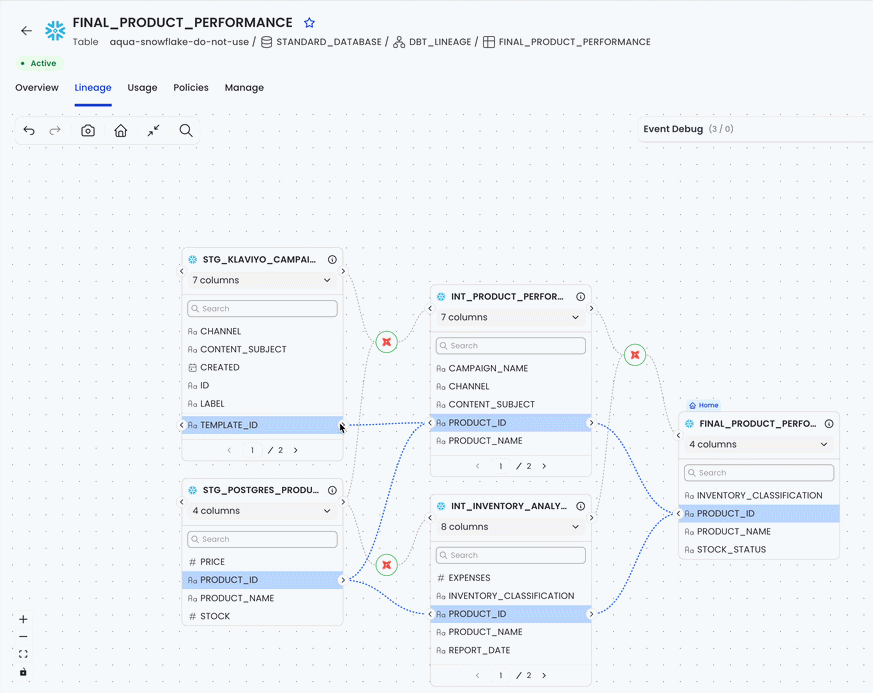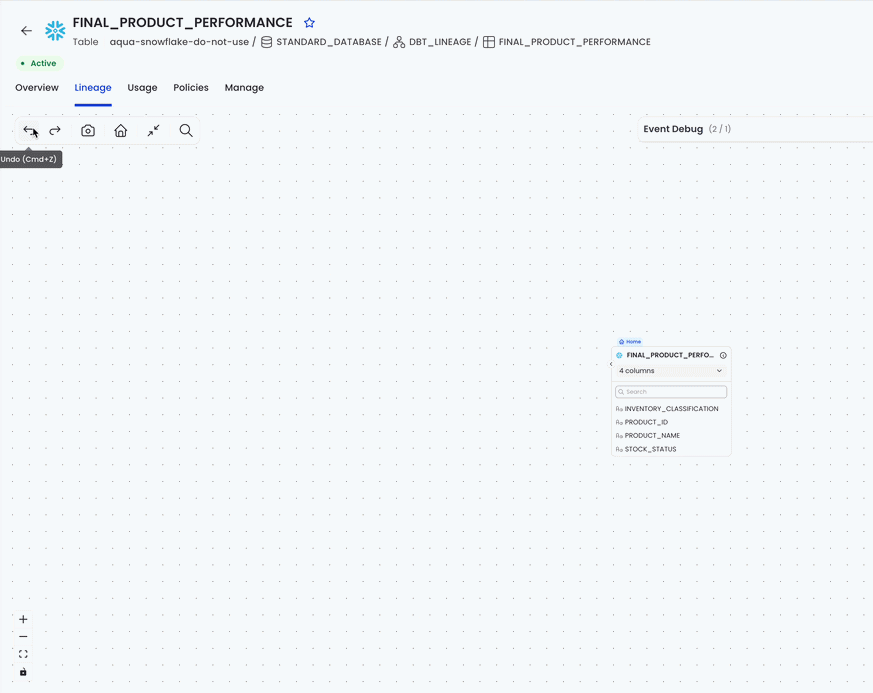
That means the timeline looks like many internal steps, but the user gets one undoable action:
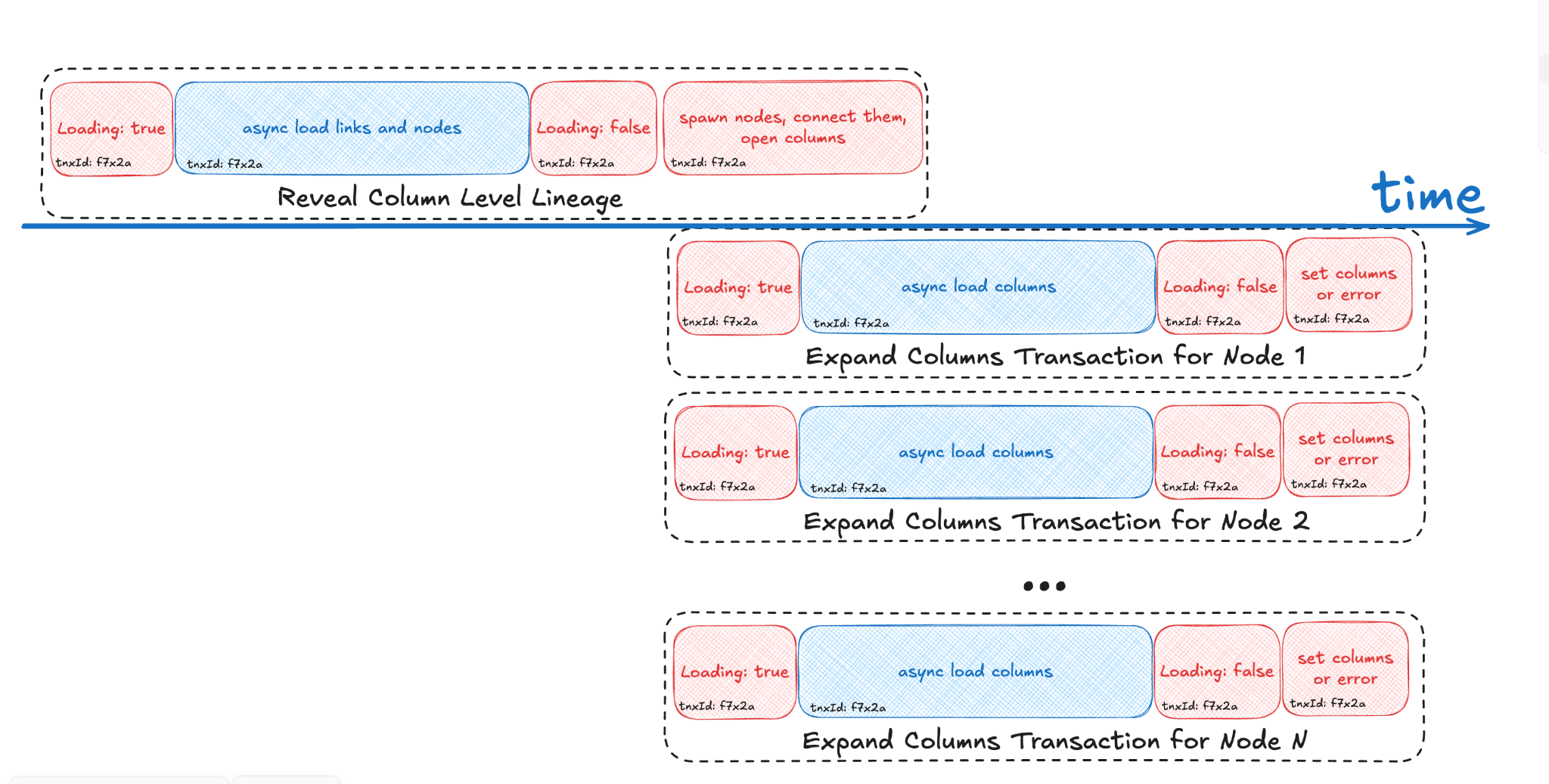
The implementation is intentionally simple. The event factory resolves the transaction ID when the event is created. Then the event store groups events with matching _txId. The column expansion flow can either create its own transaction or join a parent one: getTransactionId: () => transactionId ?? buildExpandingColumnsTransactionId(nodeId)
So when column expansion is triggered directly, each table expansion is its own undoable unit. But when it is triggered as part of column-level lineage reveal, it receives the parent transaction ID and becomes part of the larger undo step.
This is less like true nested transactions and more like transaction composition by shared ID. Multiple async flows can run at different times, but as long as they emit events with the same transaction ID, the undo system treats them as one semantic action. Undo does not reverse each child operation individually; it removes the whole transaction from history and replays the remaining operation log from the latest checkpoint.
Why This Architecture Works for Us
Selective Tracking Supports Migration
We do not track every Zustand mutation automatically. Only mutations that emit configured flow graph events become undoable. That tradeoff gives us control over undo semantics and lets us migrate incrementally.
This is especially important for a large graph UI where not every state change should be user-visible history. Some mutations are meaningful user intents; others are internal UI mechanics. The architecture lets us decide what is worth tracking now, while still leaving a clear path for future features to join the undo system by emitting events.
Type Safety Keeps Extensions Honest
The contract lives at the call site, and that call site stays lightweight: developers describe what happened, attach a snapshot, and TypeScript infers the rest. No generic plumbing, no payload casts - the snapshot shape and the handler stay aligned by construction. Different parts of the product operate in different scopes: some events affect the whole graph, others only a localized slice (pagination within a single node is one example). Those scopes stay separate, but the emission pattern is the same. When a new vertical slice needs its own scope, it plugs into the same model; the type system grows with it instead of forcing a rewrite across existing emitters.
One Apply Path, Minimal Runtime Overhead
Each event uses the same forward mutation path when it is first emitted and when it is replayed during undo/redo. We do not maintain separate inverse logic for every action.
The subscription is also created once when the event store is wired to the Zustand store, so we avoid component-level useEffect cleanup and re-subscription concerns during React renders.
Bounded History Through Snapshot Compaction
The history stack has a fixed limit. When it overflows, we do not simply drop old behavior from the system. Instead, we fold the oldest history entry into a rolling baseSnapshot using the same forward-apply logic, then remove that entry from the undoable window.
Undo works by moving the latest transaction from history to redoStack, then deriving state again from baseSnapshot by replaying the remaining history. Redo moves the transaction back and derives state the same way. There is no separate “current cursor” state to maintain.
Scales With Features That Emit Events
New features can become undoable by emitting replay-safe events. They do not need to implement custom inverse commands, and they do not need to understand the full orchestration layer.
The main requirement is discipline: event handlers must be snapshot-driven and closure-free, because the same event may run immediately and later during replay.
The Tradeoff
We gave up “track everything automatically” in favor of explicit, semantic tracking. That matches the product constraint: undo should roll back user intent, not every internal state transition.
What we gained is a system that can grow feature by feature: transaction batching for async flows, bounded memory through checkpointing, and a single replay model that is easier to reason about than maintaining manual inverse logic for every graph operation.
Key Lessons
Overall, this project surfaced a few lessons that shaped the design we shipped:
Snapshot-based undo works well for small, serializable state trees, but it breaks down quickly when the state is a large graph with derived infrastructure and async mutations. For our lineage canvas, the better fit was a pragmatic middle ground: semantic operation replay from a rolling checkpoint. We do not store a full snapshot per step, and we do not implement inverse commands for every action. Instead, we record forward operations, batch related events by transaction ID, and rebuild state by replaying the remaining history.
That made a few things clear: defining the user-facing undo unit matters more than choosing a textbook pattern; ID-based transaction grouping is more reliable than timing heuristics; replay safety depends on snapshot-driven, closure-free handlers; and TypeScript helped make the migration safer by catching contract drift early. AI tools also lowered the cost of architectural exploration, making it realistic to compare patterns like Memento, Command, and event sourcing before landing on the approach that fit our product constraints.

.png)






