
.svg)

Scaling data operations with reverse ETL: an introductory guide from a data engineer


.webp)
Every company wants to be more data-driven, but turning insights into action remains a challenge. Reverse ETL may be the missing link between your data warehouse and the business tools teams use daily.
With the widespread adoption of modern cloud data warehouses like Snowflake, organizations now have access to more data than ever before. Historically, these systems have been the domain of technical data professionals, but business teams increasingly require direct access to this information. This growing demand for operational data has fueled the rise of Reverse ETL, enabling non-technical teams to leverage data more effectively in their daily workflows.
What is reverse ETL?
Reverse ETL is a modern data integration process that moves data from a central data warehouse, like Snowflake or Databricks, back to operational business tools, like CRMs (HubSpot, Salesforce), Communication tools (Slack), and/or finance tools. This process emerged as a critical component of the modern data stack, addressing the need to close the analytics-to-operations loop and enable operational analytics and even database replication. By facilitating the flow of enriched data from centralized repositories to everyday business tools, Reverse ETL empowers teams across an organization to make data-driven decisions and take action based on the latest insights
Reverse ETL vs ETL
Extract, Transform, Load (ETL) and Reverse ETL are two distinct data integration processes that serve different purposes within an organization's data strategy.
ETL (Extract, Transform, Load): ETL is a traditional process that extracts data from various source systems, transforms it, and loads it into a centralized data warehouse. This approach enables organizations to consolidate data from multiple sources for comprehensive analysis and reporting. By centralizing data, ETL facilitates business intelligence efforts, allowing data teams to derive insights that inform strategic decision-making.
Reverse ETL: In contrast, Reverse ETL takes the transformed data residing in the data warehouse and syncs it back to operational tools such as Customer Relationship Management (CRM) systems, marketing platforms and other business applications. This process ensures that enriched data is accessible across various applications, enabling broader use within the organization.
By doing so, reverse ETL empowers business teams to leverage up-to-date insights directly within their daily workflows, facilitating real-time, data-driven actions.
The chart below summaries key differences between reverse ETL and ETL.
Understanding these differences is crucial for organizations aiming to implement a modern data stack that not only analyzes data but also seamlessly integrates insights into everyday business processes.
Technical architecture and components of reverse ETL
The technical architecture of Reverse ETL systems comprises several key components:
Connectors
Connectors are integral to reverse ETL platforms, enabling seamless data transfer between the data warehouse and various operational tools. They facilitate the extraction of data from the warehouse and its subsequent loading into target applications. Common destinations supported by Reverse ETL connectors include many of the following systems
You can read a complete walkthrough of building a manual Reverse ETL pipeline here.
SQL models in reverse ETL: structuring data for operational use
In Reverse ETL processes, SQL models play a pivotal role in preparing and structuring data for seamless integration into operational systems. These models are essentially SQL queries or scripts that define the specific data sets that will be extracted from the data warehouse, transformed as necessary, and then synced to target applications.
Below is a view of the SQL model configuration in Matia Reverse ETL
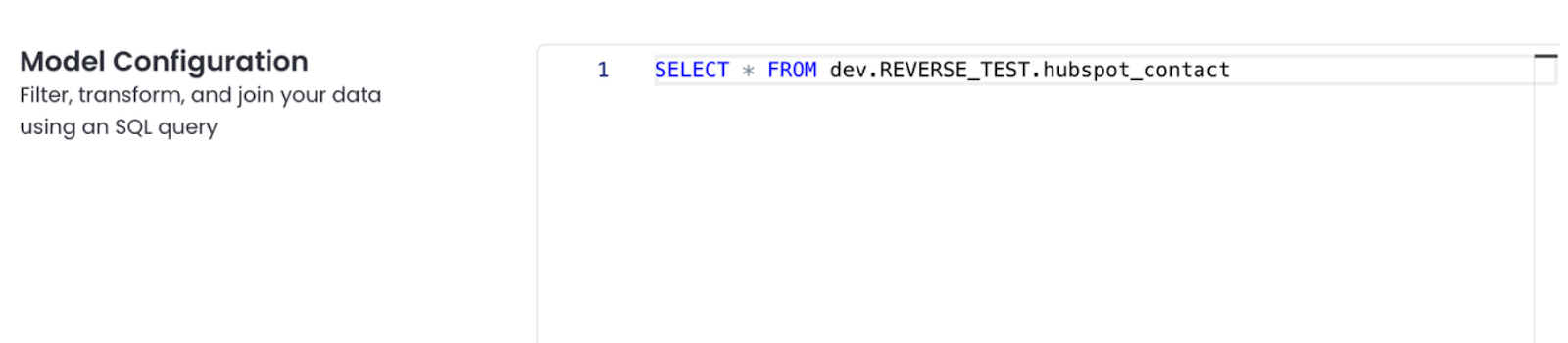
Role of SQL models in reverse ETL
- Data Selection: SQL models allow data teams to precisely define which data to extract from the warehouse, ensuring that only relevant and necessary information is prepared for syncing.
- Data Transformation: Through SQL queries, data can be transformed to match the schema and requirements of the destination systems, facilitating smooth integration.
- Data Filtering and Aggregation: SQL models enable filtering and aggregation of data to create tailored datasets that meet the specific needs of business teams.
The result of the SQL query above is shown below:
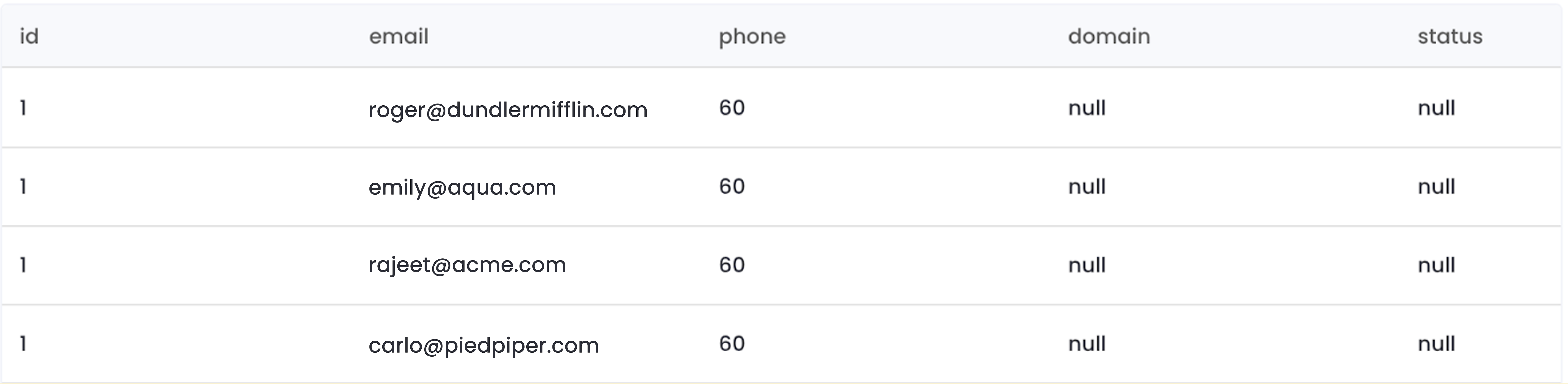
Complex SQL models often go beyond simple filtering and involve joining multiple tables, applying window functions, or performing aggregations to create actionable datasets for business tools. For instance, instead of just pulling recent contacts, you might calculate customer lifetime value, rank leads based on engagement scores, or enrich contact records with data from product usage tables. These more advanced queries ensure that the data synced to operational tools is not only current but also context-rich, enabling sales, marketing, or support teams to make smarter, data-driven decisions.
Data field mapping in reverse ETL
Before syncing data to operational tools, it's necessary to map the fields it to align with the specific schema and requirements of the target system. To do this, you must map the warehouse to the corresponding fields in the destination application, ensuring compatibility and consistency. For instance, customer segmentation data in the warehouse might be reformatted to match the structure expected by a CRM system.
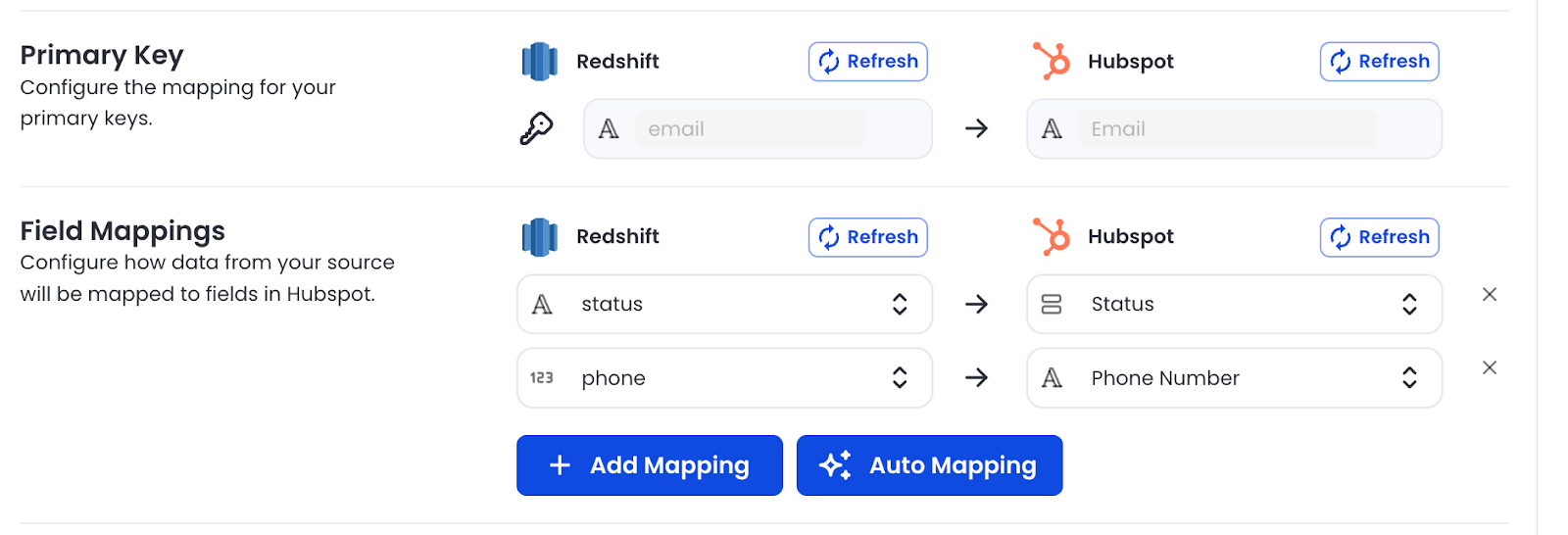
Sync mechanisms in reverse ETL: mirror syncs and insert-only syncs
Sync mechanisms determine how data is transferred from the data warehouse to operational tools. Two common approaches are Mirror Sync and Upsert Sync, each catering to different data synchronization needs.
.webp)
Mirror Syncs
Mirror Syncs aim to replicate the data in the operational tool to match exactly what's in the data warehouse. This method involves inserting new records, updating existing ones, and deleting records in the destination to reflect the current state of the source data.
Mirror syncs are ideal for scenarios where the destination system requires an exact replica of the source data, ensuring consistency across platforms. For example, let’s say your customer success team needed real-time data about NPS scores in Salesforce in order to activate campaigns based on certain scores. If a score is low, you may want the customer success team to reach out ASAP to better understand issues and if a high score, you may want to ask for a review on a third party site, or put your customer in a promoter campaign. That may be collected in the product (or another third party app), and sent to Snowflake, but Snowflake isn’t easily accessible by most business users. With an RETL platform, you can configure scores to automatically update salesforce (and even trigger a slack notification) once done.
While having this data in end tools can be helpful to business users, mirror syncs can be resource-intensive and costly. This is because they require frequent updates, including inserting, modifying, and deleting records, to keep the destination system fully synchronized with the data warehouse.
Upserts
Upsert, a combination of "update" and "insert," focuses on adding new records and updating existing ones in the destination system without deleting any data. This approach ensures that the destination contains the most recent information without removing any records.
- Use Case: Suitable for situations where it's crucial to keep data updated and add new entries, such as maintaining up-to-date customer information in a CRM system.
- Considerations: Since Upsert doesn't delete records, discrepancies between the source and destination data can occur over time. It's crucial to implement data validation mechanisms to monitor and address any inconsistencies.
Mirror Sync vs. upserts: a comparison
Monitoring quality, observability and handling errors
Your data is only useful if it’s accurate. To maintain the reliability of data flows, some Reverse ETL systems incorporate monitoring and error handling components
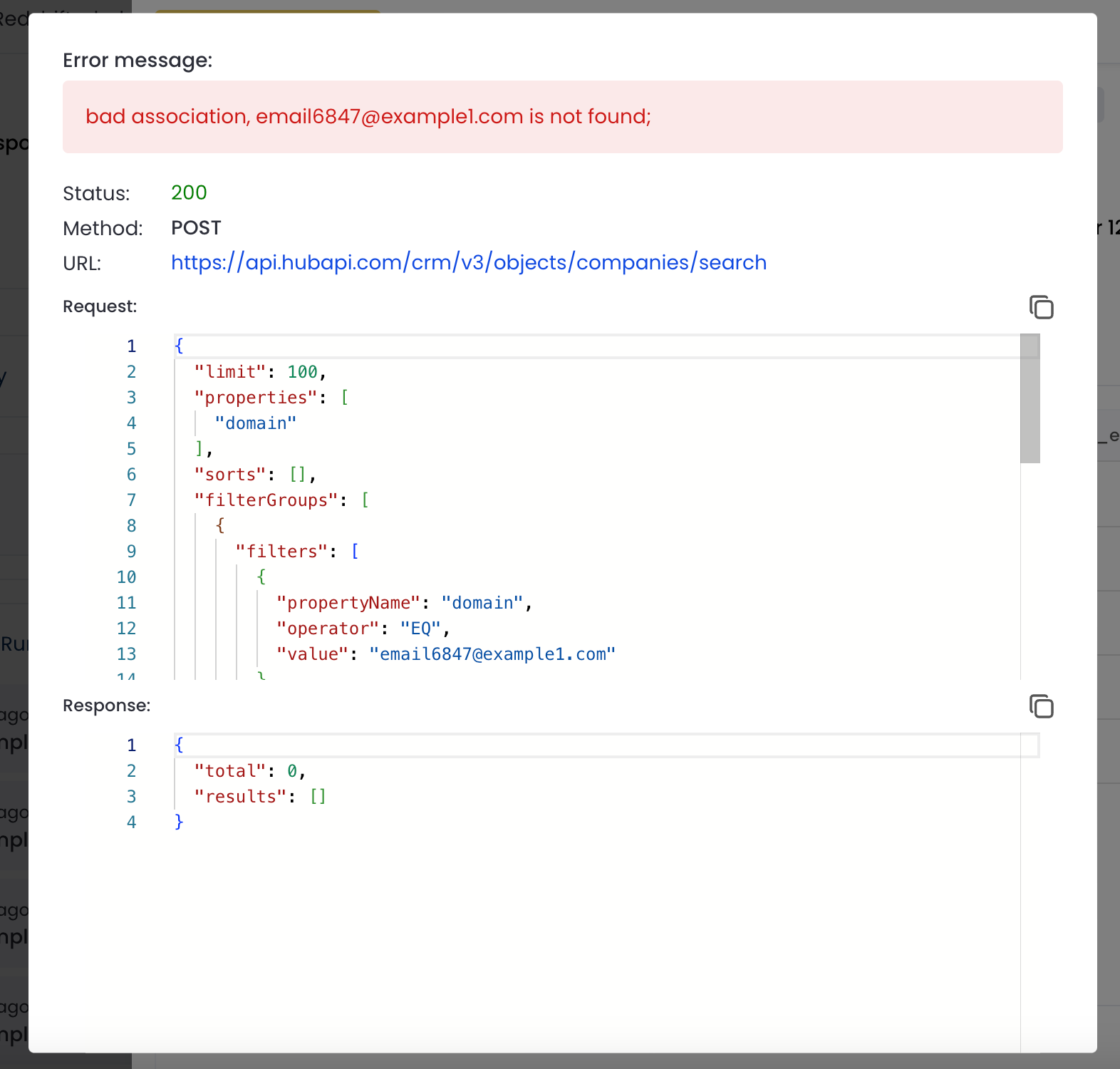
Monitoring tools track the status of data sync processes, providing visibility into successful records transfers, rejected records from the 3rd party applications, and Invalid records in the warehouse such as duplications or invalid nulls. They help ensure data quality. The Matia platform allows for observability to be built into every step of its data pipelines, including reverse ETL.
Error handling processes involve error handling and debugging mechanisms that detect issues such as data mismatches or transfer failures. They may include automated retries, logging of errors for further investigation, and notifications to data engineers for prompt resolution.
Implementing comprehensive monitoring and error handling ensures data integrity and minimizes disruptions in business operations. Many tools, such as Matia, include built-in observability capabilities that can remedy errors.
In the Matia Platform, we’ve built a robust debugging mechanism for handling “rejected records.” The platform exposes both the API request and response payloads, giving customers full visibility into exactly why a record was rejected. This transparency makes it easy for users to identify mismatches in their data and resolve issues on their own, quickly and efficiently.
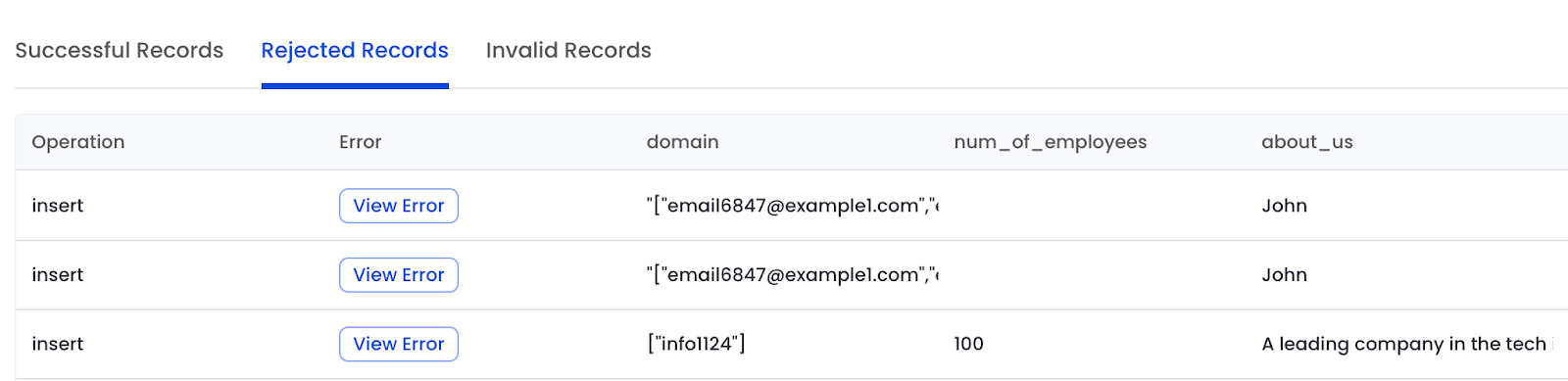
By integrating these components, connectors, data transformation layers, sync mechanisms, and monitoring tools, Reverse ETL systems effectively bridge the gap between data warehouses and operational applications, empowering organizations to act on insights with confidence.
Real-world use cases and impact of reverse ETL
Reverse ETL enables organizations to operationalize their data by syncing information from data warehouses to various business tools, enhancing functions such as personalized marketing, sales prioritization, and customer service optimization. Below are specific applications illustrating how data flows from warehouses to operational tools.
Personalized marketing
By leveraging Reverse ETL, marketing teams can deliver tailored content and campaigns to individual customers:
- Data flow: Customer behavior and interaction data are stored in the data warehouse. Reverse ETL processes extract this data and sync it to marketing platforms like Marketo or Mailchimp.
- Application: Marketers use this enriched data to create personalized email campaigns, product recommendations, and targeted promotions, enhancing customer engagement and conversion rates.
Sales prioritization
Sales teams can focus their efforts more effectively by utilizing Reverse ETL to access valuable customer insights:
- Data flow: Product usage statistics and customer engagement metrics are consolidated in the data warehouse. Reverse ETL syncs this data to CRM systems such as Salesforce.
- Application: Sales representatives receive real-time alerts about high-potential leads or customers showing signs of churn, enabling timely and prioritized outreach.
Customer service optimization
Enhancing customer support is achievable through Reverse ETL by providing service teams with comprehensive customer data:
- Data flow: Customer purchase histories and support ticket information are aggregated in the data warehouse. Reverse ETL syncs this data to customer service platforms like Zendesk.
- Application: Support agents access a unified view of customer interactions, allowing for personalized and efficient responses to inquiries and issues.
Unlocking the full potential of reverse ETL
Reverse ETL has emerged as a crucial component of the modern data stack, bridging the gap between analytical insights and real-world operational execution. By enabling businesses to move data from centralized warehouses into frontline applications, Reverse ETL empowers teams to act on the latest data without requiring technical expertise.
From personalized marketing and sales prioritization to enhanced customer support, Reverse ETL ensures that data is not just stored and analyzed but actively leveraged to drive business outcomes. Its flexible architecture, encompassing key components like connectors, SQL models, sync mechanisms, and monitoring tools, provides a scalable and reliable foundation for real-time data activation.
Reverse ETL can be time consuming to execute manually (see the guide here if you want to try), which is why solutions such as Matia exist.

.png)






